
Anonos' patented Variant Twins provide accuracy of results comparable to processing unprotected cleartext but in compliance with GDPR and Schrems II international data transfer Pseudonymisation requirements. Results are virtually identical on every measure –with Variant Twins providing obviously enhanced resistance to re-identification.
Evolution of Technology Enforced Privacy Controls
Introduction
 Mark Little, Chief Data Strategist, Anonos
Mark Little, Chief Data Strategist, Anonos
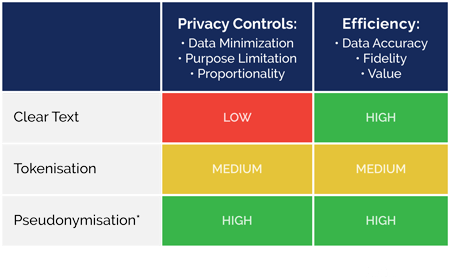
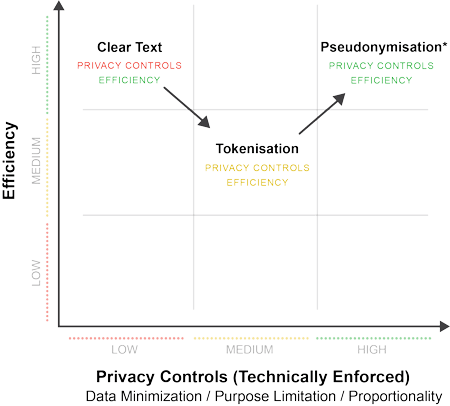
The public’s interest in the reasonable expectation of privacy is met when personal data remains private: within reasonable limits, the data cannot be used to single out, or to inferentially identify or link personal data to a particular data subject.1 Historically, privacy was maintained by contractually limiting the scope for using intelligible versions of data in clear text format. However, personal data is now increasingly used for advanced secondary processing (including sophisticated analytics, AI, ML, data sharing and enrichment) where consent alone is not meaningful.2 Yet, the public maintains the same interest in privacy.
One long-used method in protecting privacy has been consistently substituting the same token for a given direct identifier each time it occurs - i.e., "tokenisation." While perhaps useful decades ago, this approach was long known to no longer provide meaningful protection.3 Historically, tokenisation was sometimes called "pseudonymisation." However, the latter term did not have the benefit of any statutory underpinning.
That changed with the arrival of the EU General Data Protection Regulation (GDPR). While many are aware that the GDPR for the first time established at the EU level a formal regulatory definition for Pseudonymisation, few are aware of how significantly that definition changes what must be done to advance a claim that a data set has been Pseudonymised in compliance with the GDPR. To fully appreciate the magnitude of the changes, consider the following:
Anonos technology uses patented technology to achieve GDPR Pseudonymisation by enabling the assignment of dynamically generated pseudonyms to both direct and indirect identifiers. But it goes further, by combining this approach with traditional anonymisation techniques along with patented enhancements to Pseudonymisation to enable Controlled Relinkable Data6 that ensures no loss in the utility of source data--which by definition anonymous data cannot do--while providing resistance to re-identification that is comparable or superior to other approaches. The data assets that deliver this powerful combination are called Variant Twins. 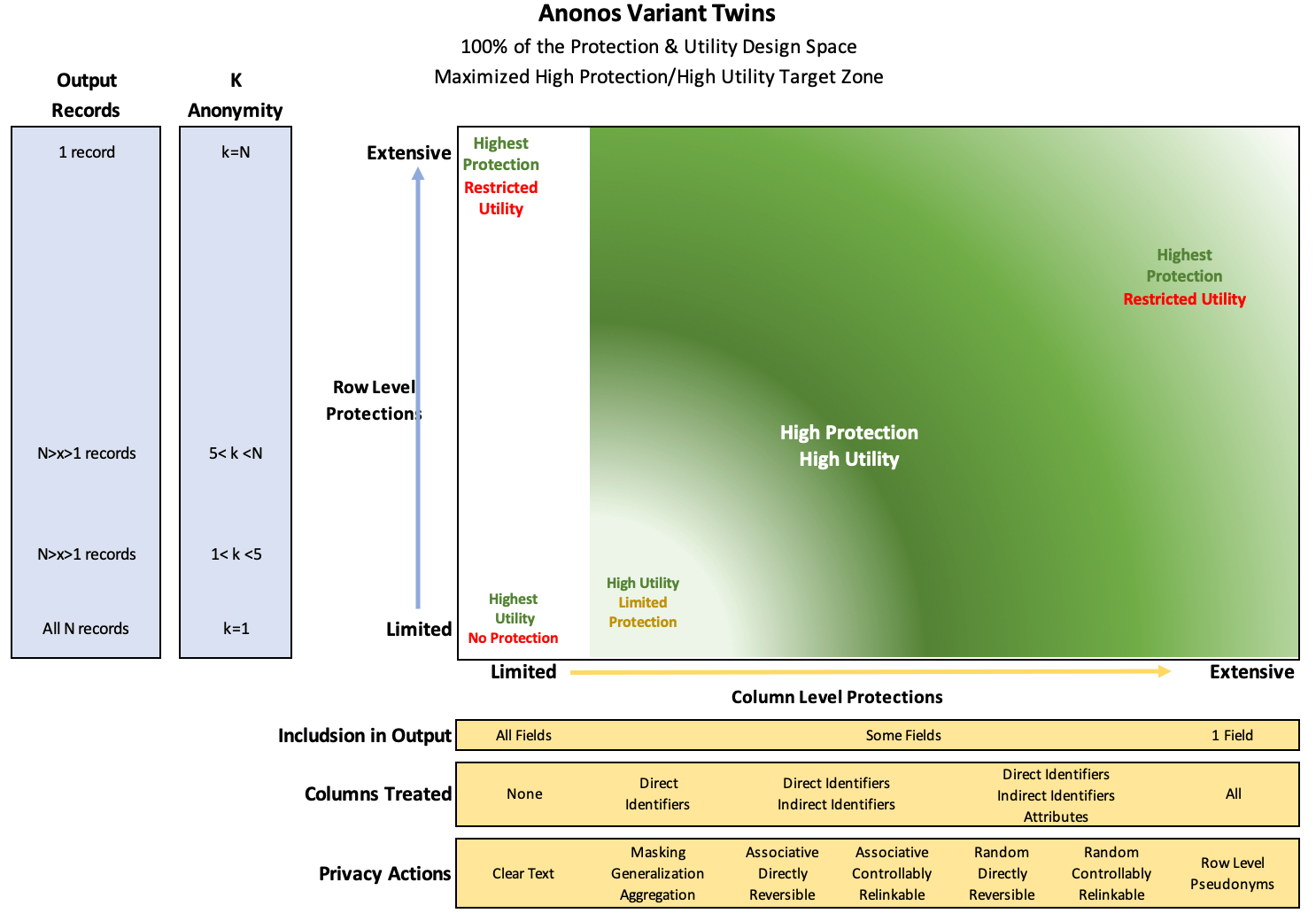
What follows is an analysis of the comparative utility of Variant Twins and the corresponding original clear text data sources for Machine Learning and AI.
Analysis: “The Comparative Utility of Clear Text and Variant Twins in Machine Learning and Artificial Intelligence Model Development”
 Mike Nemke, Director of AI & Machine Learning, Aptive Resources
Mike Nemke, Director of AI & Machine Learning, Aptive Resources
Mike is the Director of AI & Machine Learning at Aptive Resources where he leads the rapidly expanding Data Science Practice and ML Product development efforts for several large government clients. Prior to his time with Aptive Resources, Mike spent 5 years working as a Lead Data Scientist for startups and consulting firms in the SF Bay Area. Mike also has an MS in Data Science from Northwestern University.
Motivation
Data science and machine learning practices are emerging and operating in a complex space, and Data Science professionals are subject to the same inherent systemic and cognitive biases6 as any other role. Unfortunately, due to the increasingly automated and predictive nature of data work, those otherwise marginal biases, conscious or otherwise, and their effects, are magnified. Additionally, these data sets frequently contain personal data that is increasingly subject to restrictions in processing under emerging data protection and privacy regulations. In order to minimize possibly harmful bias and comply with data privacy and protection requirements for work produced by myself and my team of Data Scientists, Data Analysts, and Machine Learning Engineers, I decided to test options for masking or pseudonymisation of the data we work with.
Situation
Given an artificially generated dataset with 100,000 job applicants, we want to predict, without exposing their personal information, whether they will accept or decline a job offer. Given the significant amount of personal information in the form of direct and indirect identifiers, and a desire to remove systemic biases from hiring practices, we want to compare analysis of the clear text dataset against a pseudonymised dataset (i.e., an Anonos Variant Twin) to assess the relative utility given the significantly enhanced resistance to unauthorized re-identification of the Variant Twin.
Analysis Goal
Analyze and measure the performance of analytical models on the clear text dataset and the Variant Twin. The analysis performed is a series of classification models to identify whether candidates will accept or decline a job offer.
Intro to the data
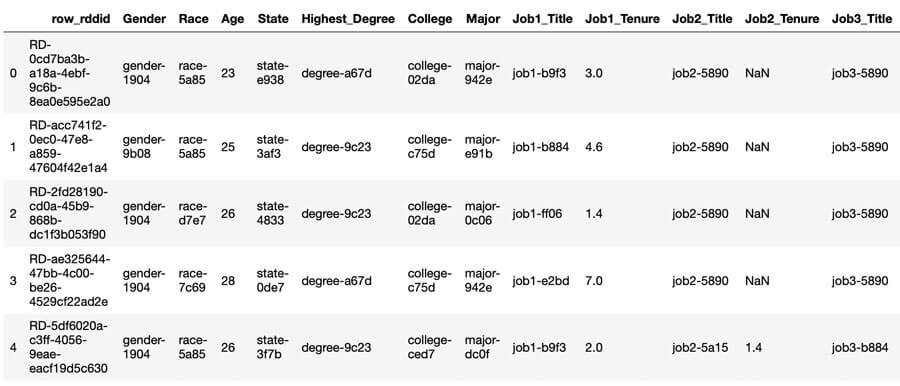
The original clear text data consisted of 100,000 fictitious job applicants and included name, email, age, gender, race, location, education, work experience, as well as application and interview specific data. The Variant Twin dataset used the original data, but with pseudonymised replacements for gender, race, state, degree, college, college major, job titles, job tenures, job applied for, and application source. The name, email, city, and interviewer note data were removed in the Variant Twin generation process and age remained unchanged. Non identifiable attribute information (e.g., interview ratings) also remained unchanged.
Clear Text Data
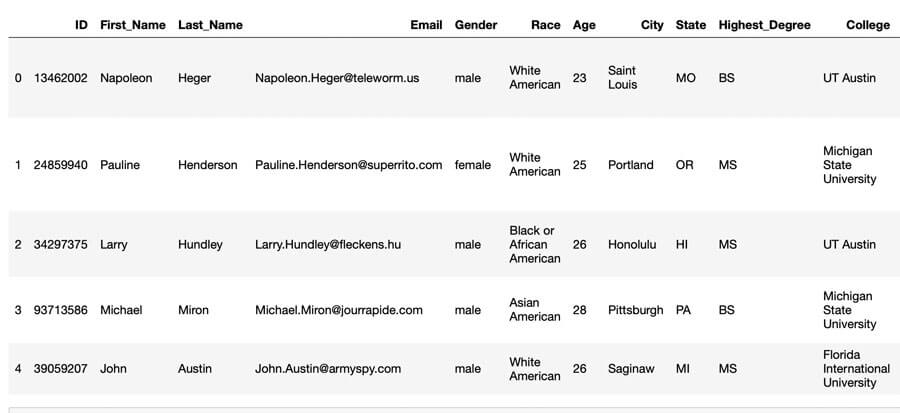
Variant Twin dataset
Methodology
Tools used
All of the code for this analysis was completed in python using Jupyter notebooks. The packages used for this analysis include Matplotlib and Seaborn for data visualizations, NumPy and Pandas for shaping and managing the data, and TensorFlow and Scikit-learn for modeling and analyzing the data.
Data Preparation
The target variable for this analysis is the ‘Decision’ variable. The Decision variable was either ‘Accepted’ or ‘Declined’ in both datasets and was converted to a binary variable with ‘0’ mapping to ‘Declined’ and ‘1’ mapping to ‘Accepted’. All candidates that did not receive an offer, and therefore had a null decision value, were dropped from the analysis. Both datasets contained 28,054 instances with either a ‘0’ or ‘1’ decision value.
Due to null values in the unmasked dataset, the following columns were dropped from both datasets: Terminated, Job2_Title, Job2_Tenure, Job3_Title, Job3_Tenure, Offer. The ‘Terminated’ variable indicated an employee that accepted an offer and had later terminated employment. That means the variable is only viable for the candidates that accepted an offer. The job title and tenure columns were largely null. Finally, the ‘Offer’ variable was ‘yes’ for any candidate who would have ‘Accepted’ or ‘Declined’ an offer, thereby providing no analytical value in this exercise.
In order to use the categorical variables in the datasets to predict whether a candidate would accept or decline an offer, the following variables were encoded as categorical variables using Pandas get_dummies() function: Gender, Race, State, Highest_Degree, College, Major, Job1_Title, Job_Applied_For, and Source.
The input variables used in this analysis were: Gender, Race, Age, State, Highest_Degree, College, Major, Job1_Title, Job1_Tenure, Job_Applied_For, Source, Assessment_Score, Interviews, Interview_Score_Avg, Recruiter_App_Eval, Cycle_Time_Days. Following variable encoding, there were a total of 161 input variables.
Modelling Technique 1: Random Forest
The datasets were imbalanced with 19,660 offers accepted and 8,394 offers declined. Due to the imbalance, the first classification technique used was a Random Forest Classifier using a Scikit-learn module (link). Three separate approaches were taken to running the Random Forest Classifiers, first using no hyperparameter tuning, the second using class_weight=’balanced’, and finally class_weight=’balanced_subsample’. For this hyperparameter:
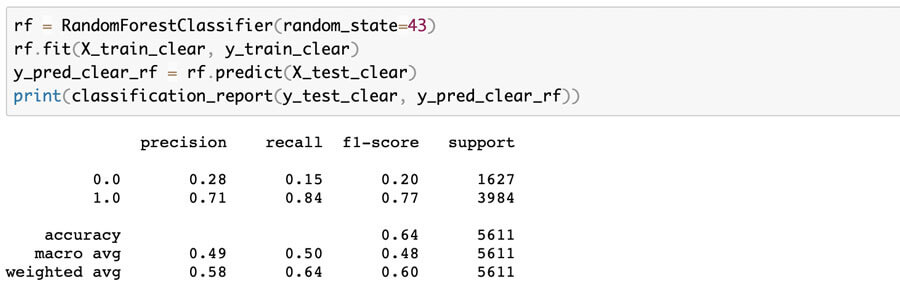
Clear Text Random Forest Classifier:
Variant Twin Random Forest Classifier:
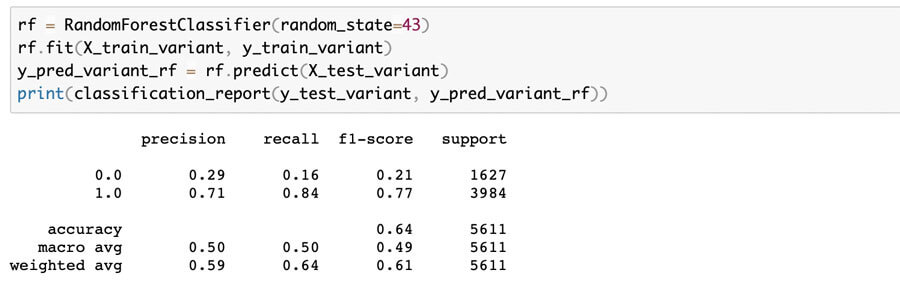
As you can see from the figures above, precision, recall, and f1-scores are all virtually the same for models with the class_weight hyperparameter omitted. The same outcome resulted for both the balanced and balanced_subsample runs.
Modeling Technique 2: Neural Network
In preparation for the neural network, both datasets were converted to arrays and scaled using the Scikit-learn standard scaler module (link). The model was developed using TensorFlow and Keras. 3 dense layers, and 2 dropout layers made up the model, with the final dense layer using a sigmoid activation function. The hyperparameters used for the NN: Adam optimizer with a learning rate of 1e-3, and binary cross entropy as the loss function. For each dataset, the model was set to run 100 epochs with a batch size of 500.
Clear Text NN Model:
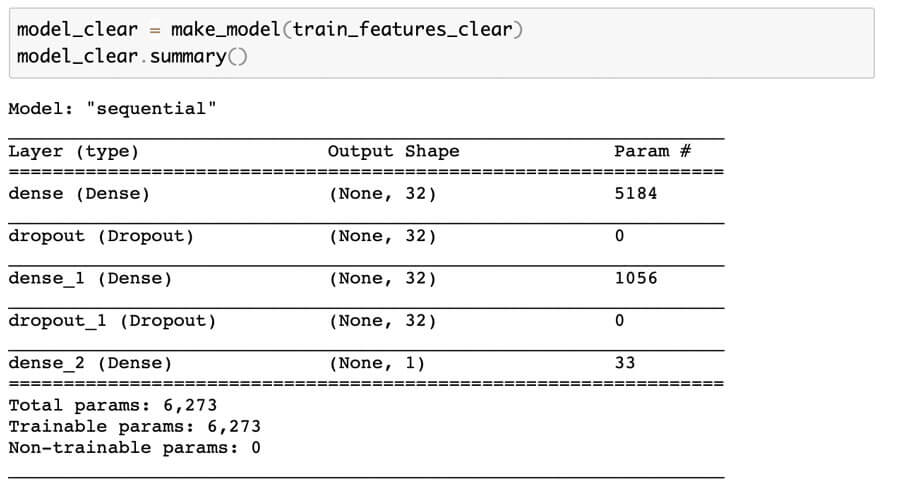
Clear Text Neural Network Classifier Outcomes:

Variant Twin Neural Network Classifier Outcomes:

There are inherent variations in the outcomes due to the use of neural networks, but as shown in the figures above, the Variant Twin returned results very comparable to clear text, underperforming modestly in predicting the majority class (“Accepted’ offers) and slightly outperforming in predicting the minority class (‘Declined’ offers).
Modeling Technique 3: Logistic Regression
Using the Scikit-learn logistic regression module, both datasets were used to fit and predict the decision variable.
Clear Text Logistic Regression Outcomes:
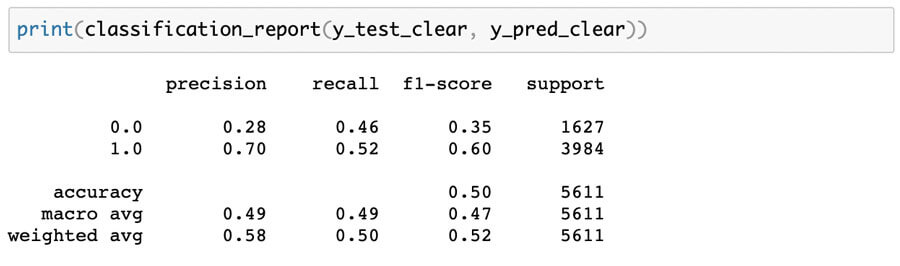
Variant Twin Logistic Regression Outcomes:
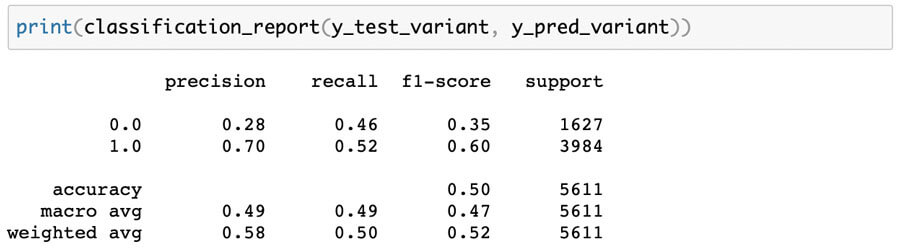
As can be seen in the figures above, the outcomes were identical.
Discussion of Results
Consistent results across both datasets
In this analysis, we used random forests, neural networks, and logistic regression to classify whether a job candidate would accept an offer with 2 datasets. One dataset was the original clear text data and the other was an Anonos Variant Twin. The analysis shows that the Anonos Variant Twin performed virtually the same as the clear text data from which it was derived for machine learning tasks. The differences in model performance were negligible and the only real variance came from inherently variable models (neural networks).
Conclusions For Machine Learning tasks, Anonos Variant Twins provide performance comparable to clear text data. Both datasets were virtually identical on every measure – with Variant Twins providing obviously enhanced resistance to re-identification.
In my work with Aptive Resources as Director of AI & Machine Learning, I commonly lead the development of data science and machine learning models and products for large U.S. government clients. Our clients prioritize privacy of personal data in all of our projects and based on my experience with competitive products and approaches, Anonos’ Variant Twins approach is best in class. Based on our experience with this testing, we plan on adopting Anonos technology for analytics projects with datasets rich in personal data.
Footnotes:
[1] Sean Clouston, Data Privacy in An Age of Increasingly Specific and Publicly Available Data: An Analysis of Risk Resulting from Data Treated Using Anonos’ BigPrivacy Methodology, US Federal Trade Commission Response #45 to Request For Research Presentations For the PrivacyCon Conference (October 9, 2015). Available at https://www.ftc.gov/policy/public-comments/2015/10/09/comment-00045
[2] Anne Josephine Flanagan, Jen King, and Sheila Warren, Redesigning Data Privacy: Reimagining Notice & Consent for Human-Technology Interaction (July 2020). World Economic Forum White Paper. Available at https://www.weforum.org/reports/redesigning-data-privacy-reimagining-notice-consent-for-humantechnology-interaction
[3] Paul Ohm, Broken Promises of Privacy: Responding to the Surprising Failure of Anonymization (August 13, 2009). UCLA Law Review, Vol. 57, p. 1701, 2010, U of Colorado Law Legal Studies Research Paper No. 9-12, Available at https://ssrn.com/abstract=1450006
[4] GDPR Article 4(5), https://eur-lex.europa.eu/legal-content/EN/TXT/HTML/?uri=CELEX:32016R0679&rid=3#d1e1489-1-1
[5] GDPR Article 4(1), https://eur-lex.europa.eu/legal-content/EN/TXT/HTML/?uri=CELEX:32016R0679&rid=3#d1e1489-1-1
[6] Michael Hintze and Gary LaFever, Meeting Upcoming GDPR Requirements While Maximizing the Full Value of Data Analytics (January 2017). Available at http://dx.doi.org/10.2139/ssrn.2927540
[7] Shira Mitchell, Eric Potash, Solon Barocas, Alexander D’Amour, and Kristian Lum. Prediction-Based Decisions and Fairness: A Catalogue of Choices, Assumptions, and Definitions (2020). Available at https://arxiv.org/pdf/1811.07867.pdf.

