

Processing Identifying Data is Unlawful in Many Situations; GDPR Pseudonymisation is State of-the-Art for Mitigating “Cloud Risk” and “Lawfulness of Processing Risk” Without Losing Value
By: Magali Feys[i]
CLOUD RISK: You Can No Longer Process Identifying EU Personal Data in the US Cloud
In late June, the European Data Protection Board (“EDPB”)[1] and the European Commission (“EC”) [2] reaffirmed the July 2020 Schrems II Court ruling by the Court of Justice of the European Union (“CJEU”) that EU personal data must be technologically protected when in use; you cannot process unprotected versions of identifying data (i.e., “cleartext”) when engaged in international data transfer to Third Countries.[3]
1. The Schrems II ruling did not require new Standard Contractual Clauses (SCCs).
1.1 The CJEU mandated that the processing of EU personal data cannot reveal the identity of individual data subjects in countries that (i) are not members of the European Economic Area (EEA), (ii) have not received an EU Adequacy Decision, or (iii) otherwise are found not to provide an adequate level of protection.
1.2 The CJEU requirement for supplementing SCCs with measures to prevent disclosing identities of data subjects went into effect immediately in July 2020.
2. The EDPB clarified that the Schrems II requirements for protecting EU data subject identities can be satisfied using GDPR Pseudonymisation, including cloud services.[4]
3. In this context, the EC separately determined that new SCCs should be adopted.
4. Continuing with existing, or updating SCCs, without implementing technical controls is unlawful because government authorities in Third Countries are not bound by contractual restrictions included in SCCs.
5. Protecting EU personal data when stored or transmitted (using encryption) but processing identifying data in cleartext form (when decrypted and vulnerable) is unlawful.
6. This is a transformational shift in how data must be protected when used.
LAWFUL PROCESSING RISK: Unprotected Identifying Data Does Not Enable Lawful Advanced Processing
In late June, the EDPB Final Guidance emphasized that obligations to implement technical supplementary measures apply equally to processing internal and external to the EU.[5]
In late July, Amazon was assessed the largest GDPR fine in history – $887 Million - for unlawful processing of EU data for, among other things, failing to comply with GDPR requirements for establishing a legal basis for targeted behavioural advertising. In addition to paying the one-time fine, Amazon must remedy illegal operations within six months by implementing new technical controls that protect data when in use (by not processing unprotected identifying data) so that the processing is lawful.[6] Delays in implementation results in additional fines of $887,000 per day.
See www.Pseudonymisation.com/failure for an unofficial English translation of the 2 August 2021 letter from the Commission Nationale de l'Informatique et des Libertés (CNIL) to The Quadrature du Net regarding their original complaint against Amazon for the lack of lawful basis for its behavioural analysis and advertising targeting processes.

New Paradigm: Technical Controls Are Required that Protect Data When in Use; GDPR Pseudonymisation Protects Data When in Use Without Degrading Data Value
Evolving global regulations and court decisions require technical protection for data that travels with the data wherever it goes – including protecting data when in use.
1. Technical security (encryption) as used by organisations for years only protects data at rest and in transit, leaving data exposed when in use.
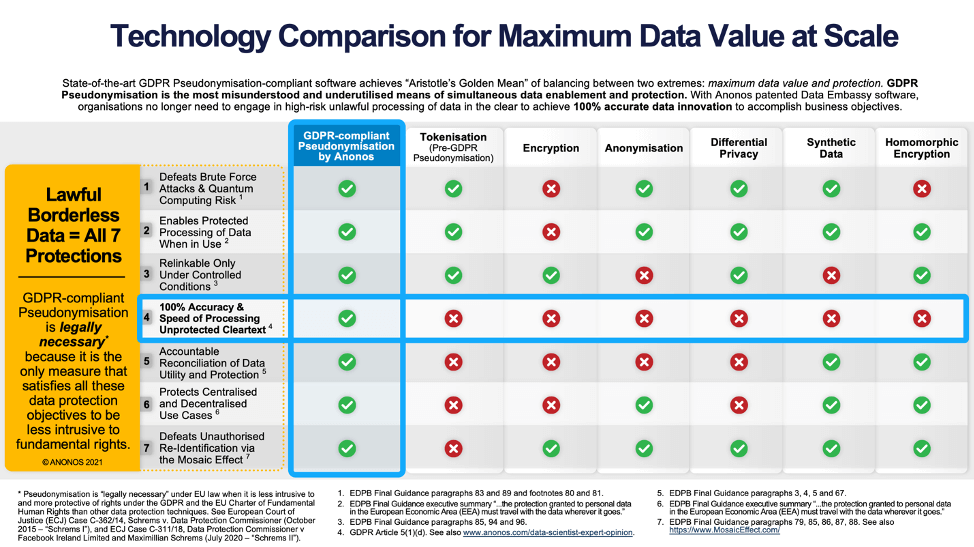
2. Organisations have chosen to process data in identifying unprotected form when in use because of significant shortcomings of traditional privacy methods for protecting data when in use – Privacy Enhancing Technologies (PETs):
3. GDPR Pseudonymisation[10] overcomes the shortcomings of traditional PETs

GDPR Pseudonymisation is the state-of-the-art[11] for complying with accuracy[12] obligations under the GDPR.
Other approaches to protecting data when in use, as required under GDPR Articles 25 and 32, degrade the accuracy of data contrary to accuracy requirements.
1. Anonymisation is not the state-of-the-art for protecting data when in use because of the availability of external data sets for augmenting purportedly anonymised data enabling unauthorised re-identification.[14] If successful in making re-identification impossible, data subjects suffer from not having the flexibility to relink to identity for authorised processing.
2. Differential Privacy is not the state-of-the-art for protecting data when in use because it: (i) is a “zero sum game” involving an inherent tradeoff between accuracy and privacy; and (ii) requires processing within restricted parameters to manage a “privacy budget” by controlling the data, use cases and users involved.
3. Encryption is not the state-of-the-art for protecting data when in use because it: (i) protects data only when it is in storage and in transit and not when it is in use; and (ii) is susceptible to brute force attacks and quantum computing risk.
4. Multi-Party Computing (MPC): MPC is not the state-of-the-art for protecting data when in use because its high computational overhead, communication demands, and elapsed processing requirements are impracticable for many applications. The delays from extended processing cycles, in time sensitive situations, may produce results that are no longer accurate, relevant, or actionable.
5. Synthetic Data: Synthetic Data is not the state-of-the-art for protecting data when in use because it: (i) provides less than 100% precision; (ii) does not enable relinking to identity for authorised processing; and (iii) requires recalibration each time the composition of source data changes.
GDPR Statutory Benefits of Pseudonymisation
The term Pseudonymisation is used fifteen times in the GDPR, compared to encryption, which is used only four times, and anonymisation which is used only three times. No other Privacy Enhancing Technologies (PETs) are referenced in the GDPR. Statutory benefits granted by the GDPR when implementing compliant Pseudonymisation include, but are not limited to, the following:[15]
Three Schrems II Use Cases for GDPR Pseudonymisation
1. Expanded Flexibility for Derogations: Pseudonymisation helps to enable lawful international transfer if organisations establish as a default the processing of Pseudonymised data whenever, wherever, and as often as possible (as required by GDPR Articles 25 and 32) so that non-Pseudonymised (i.e., identifying) data is processed only when necessary (helping to satisfy GDPR Articles 5(1)(b) Purpose Limitation and 5(1)(c) Data Minimisation), provided that:
2. Intra-EEA Processing Obligations: Pseudonymisation facilitates compliance with GDPR Article 25 and 32 obligations as well as Articles 5(1)(b) Purpose Limitation, 5(1)(c) Data Minimisation, and 6(1)(f) legitimate interests processing (by leveraging Pseudonymisation-enabled technical and organisational measures to satisfy the "balancing of interests" test[17]).
3. Preference for Non-Algorithmically Derived Pseudonyms: The use of lookup table-based pseudonyms[18] helps to overcome the risk of brute-force unauthorised re-identification by dynamically substituting non-reversible Pseudonyms for original data.
A fundamental challenge for all cryptographic data security and protection methods is thatthey encode the original information, so with sufficient “brute force” processing or quantum computing capabilities, data subjects are, at some level, re-identifiable from the encoded data. The unauthorised re-identification of pseudonyms within and between data sets via the “Mosaic Effect”[19] is defeated when different pseudonyms represent different occurrences of the same data for various purposes because there is no relationship among the pseudonyms without access to additional “look up” information kept separately. As a result, implementations using lookup-based GDPR-compliant Pseudonymisation preserve individual privacy while preventing the re-identification of de-identified data, making sustainable lawful data innovation possible even in a quantum computing world.[20]
[i] Magali Feys is the founder of AContrario Law, a boutique law firm specializing in IP, IT, Data Protection and Cybersecurity. Magali acts as a legal advisor of the Belgian Ministry of Public Health, where she advises on privacy-related matters. Magali is pursuing a doctoral thesis regarding the secondary use of medical data in compliance with GDPR requirements. She also serves as Chief Strategist of Ethical Data Use at Anonos.
[1]See EDPB Recommendations 01/2020 on Measures that Supplement Transfer Tools to Ensure Compliance with the EU Level of Protection of Personal Data Version 2.0 on 18 July 2021at https://edpb.europa.eu/system/files/2021-06/edpb_recommendations_202001vo.2.0_supplementarymeasurestransferstools_en.pdf (“EDPB Final Guidance”).
[2] See EC Implementing Decision 2021/914 on Standard Contractual Clauses for the Transfer of Personal Data to Third Countries pursuant to Regulation (EU) 2016/679 of the European Parliament and of the Council on 4 June 2021 at https://eur-lex.europa.eu/legal-content/EN/TXT/PDF/?uri=CELEX:32021D0914&from=EN (“Final SCCs”).
[3] Third countries are those that are not members of the European Economic Area (EEA), or which have not received an EU Adequacy Decision. Processing EU personal data using SaaS, PaaS or IaaS services provided by organisations organised, directly or indirectly, under the laws of the US or other third countries is considered international data transfer, regardless of the physical location of the servers on which processing occurs, due to the potential access to such data by third country government agencies.
[4] Use Case 2: Transfer of Pseudonymised Data at Paragraphs 85 - 89 of the EDPB Final Guidance. See also Italian university dissertation on this subject at https://www.SchremsII.com/epilogue.
[5] The GDPR mandatory obligations to implement technical and organizational controls that enforce the principles relating to processing of personal data, data protection by design and default, and security of processing apply to all processing – both internal and external to the EU. See GDPR Articles 5, 25 and 32 and Note 1, at Paragraphs 76 and 83.
[6] See https://www.zdnet.com/article/amazon-fined-887-million-for-gdpr-privacy-violations/
[7] See https://www.wsj.com/articles/amazon-hit-with-record-eu-privacy-fine-11627646144
[8] As made clear in the case filed by Privacy International against Acxiom and Oracle (data brokers), Equifax and Experian (credit reference agencies), and Criteo, Quantcast and Tapad (ad-tech companies) with data protection authorities in France, Ireland, and the UK. See https://privacyinternational.org/advocacy/2434/why-weve-filed-complaints-against-companies-most-people-have-never-heard-and-what
[9] See https://www.washingtonpost.com/business/2021/07/30/amazon-record-fine-europe/
[10] Prior to the GDPR, Pseudonymisation was widely understood to mean replacing direct identifiers with tokens for individual fields independently within a data set. The newly heightened requirements for GDPR-compliant Pseudonymisation in Article 4(5) now require:
(i) PROTECTING ALL DATA ELEMENTS: The definition of GDPR Pseudonymisation describes an outcome that must be achieved for a data set as a whole, not just particular fields, making it necessary to evaluate the degree of protection for all data elements in a data set, including direct identifiers, indirect identifiers, and attributes. This requirement is underscored by the fact that Article 4(5) requires protection for all “Personal Data” defined under Article 4(1) as more than personally identifying information (“PII”) and extending to “any information relating to an identified or identifiable natural person ('data subject'); an identifiable natural person is one who can be identified, directly or indirectly, in particular by reference to an identifier such as a name, an identification number, location data, an online identifier or to one or more factors specific to the physical, physiological, genetic, mental, economic, cultural or social identity of that natural person.”
(ii) PROTECTING AGAINST SINGLING OUT ATTACKS: Paragraph 85 of the EDPB Final Guidance mandates protection against "singling out" of a data subject in a larger group effectively making the use of either k-anonymity or aggregation mandatory;
(iii) DYNAMISM: complying with the requirements in Paragraphs 79, 85, 86, 87 and 88 of the EDPB Final Guidance to protect against the use of information from different datasets to reidentify data subjects necessitates the use for differing purposes of different replacement tokens at different times (i.e., dynamism) to prevent re-identification by leveraging correlations among data sets without need of the “additional information held separately” by the EU data controller (see https://www.MosaicEffect.com);
(iv) NON-ALGORITHMIC LOOK-UP TABLES: the requirement of Paragraph 89 of the EDPB Final Guidance to take into account the vulnerability of cryptographic techniques (particularly over time) to brute force attacks and quantum computing risk will necessitate the use of non-algorithmic derived look-up tables in many instances; and
(v) CONTROLLED RELINKABILITY: The combination of (i) - (iv) are necessary to meet the requirement in Paragraph 85(1) of the EDPB Final Guidance that, along with other requirements, the standard of GDPR pseudonymisation can be met if “a data exporter transfers personal data processed in such a manner that the personal data can no longer be attributed to a specific data subject, nor be used to single out the data subject in a larger group, without the use of additional information.”
[11] The GDPR requires that parties (i) use the state of the art in complying with GDPR obligations or (ii) if not, to document why they are not doing so. This obligation to use the state of the art is specifically tied to complying with the newly heightened requirements for GDPR Pseudonymisation as a critical element of both Data Protection by Design and by Default (Article 25) and Security of Processing (Article 32).
[12] Article 5(1)(d) requires that personal data be “accurate and, where necessary, kept up to date; every reasonable step must be taken to ensure that personal data that are inaccurate, having regard to the purposes for which they are processed, are erased or rectified without delay.” GDPR Pseudonymisation is state-of-the-art for protecting data when in use while ensuring accuracy. When implemented in compliance with GDPR Article 4(5) definitional requirements, pseudonymisation protects direct and indirect identifiers and attributes at the record/data set level (not just at the field level) making use of look-up tables. If the data is to be used in multiple data sets, different tables/tokens are used at different times for various purposes (i.e., dynamism) to prevent correlations among data sets that could lead to unauthorised re-identification (see https://www.MosaicEffect.com). Only by using “additional information held separately,” can data pseudonymised to GDPR standards be relinked to the identity of data subjects enabling maximum accuracy for authorised processing.
[13] See https://www.MosaicEffect.com.
[14] See footnote 2 in Annex II COMMISSION IMPLEMENTING DECISION (EU) 2021/914 at https://eur-lex.europa.eu/legal-content/EN/TXT/PDF/?uri=CELEX:32021D0914&from=EN which stipulates that anonymisation “requires rendering the data anonymous in such a way that the individual is no longer identifiable by anyone, in line with recital 26 of Regulation (EU) 2016/679, and that this process is irreversible.” The EDPB highlights that the availability of external data sets enabling unauthorised re-identification must be considered. See paragraphs 79, 85, 86, 87, 88 of Recommendations 01/2020 on Measures that Supplement Transfer Tools to Ensure Compliance with the EU Level of Protection of Personal Data https://edpb.europa.eu/system/files/2021-06/edpb_recommendations_202001vo.2.0_supplementarymeasurestransferstools_en.pdf. See also https://www.MosaicEffect.com.
[15] See www.pseudonymisation.com, www.anonos.com/gdpr-pseudonymisation-benefits and www.dataembassy.com
[16] See https://www.anonos.com/legitimate-interest
[17] Id.
[18] See for example, US Patent No. 10,043,035 Systems and Methods for Enhancing Data Protection by Anonosizing Structured and Unstructured Data and Incorporating Machine Learning and Artificial Intelligence in Classical and Quantum Computing Environments (2018) at https://patentimages.storage.googleapis.com/9e/09/4b/42552a0a31ef8d/US10043035.pdf, expanded global patent coverage is in process according to international treaties. See also https://www.anonos.com/patents
[19] See www.mosaiceffect.com/
[20] Anonos Data Embassy patented implementations of GDPR-compliant Pseudonymisation support using dynamically generated tokens for Pseudonymising data so that Pseudonyms are not reversible without the use of look-up tables.
This article originally appeared in LinkedIn. All trademarks are the property of their respective owners. All rights reserved by the respective owners.