





Data masking methods are a set of techniques designed to preserve the privacy of information and individuals. They protect against the loss, leakage, or compromise of the data. This glossary of popular data masking methods lists and describes 7 of these techniques as well as provides an overview of other techniques for protecting data.
Dynamic data masking vs. static data masking
Data masking is a traditionally popular technique that replaces sensitive data with a masked version to protect it from unauthorized access. Masked data is data that has been replaced with an accurate but inauthentic representation of the original. This means that it can be used for the same purposes as the original but does not reveal the identity or sensitive information in relatively simple use cases (i.e., those not involving more complex processing, including sharing, combining, and enriching multiple data sources and data sets).
It does not, however, prevent attackers from using other data sets to re-identify individuals via linkage attacks or inference attacks by combining the data sets based on the values in unmasked fields. Rather, it requires the data, its use, and its users to be restricted/sequestered to prevent masked records from being combined with information to reveal identities or other sensitive information.
There are two approaches to masking: dynamic and static. Dynamic data masking is a method of obscuring sensitive data in a database by replacing the sensitive data with a masked version in real-time while the actual sensitive data remains unchanged in the database.
Static data masking is a method that involves creating a copy of a database with sensitive data replaced by masked data, which is then used for testing or development purposes. The original database with sensitive data remains unchanged.
The environment (production vs. non-production), the type of processing (real-time vs batch processing), and the level of granularity in the analysis or the masking requirements usually determine the choice of technique.
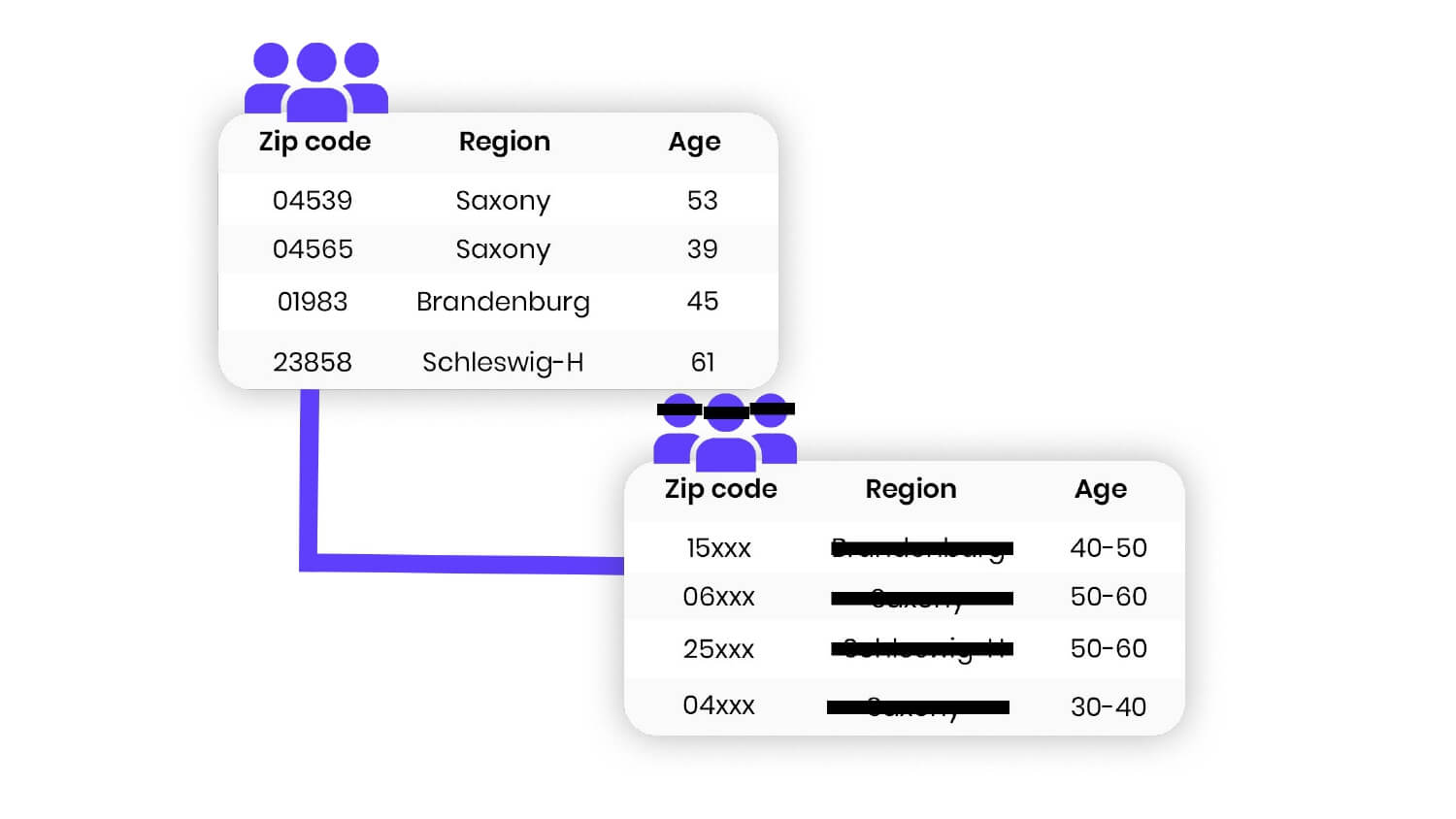
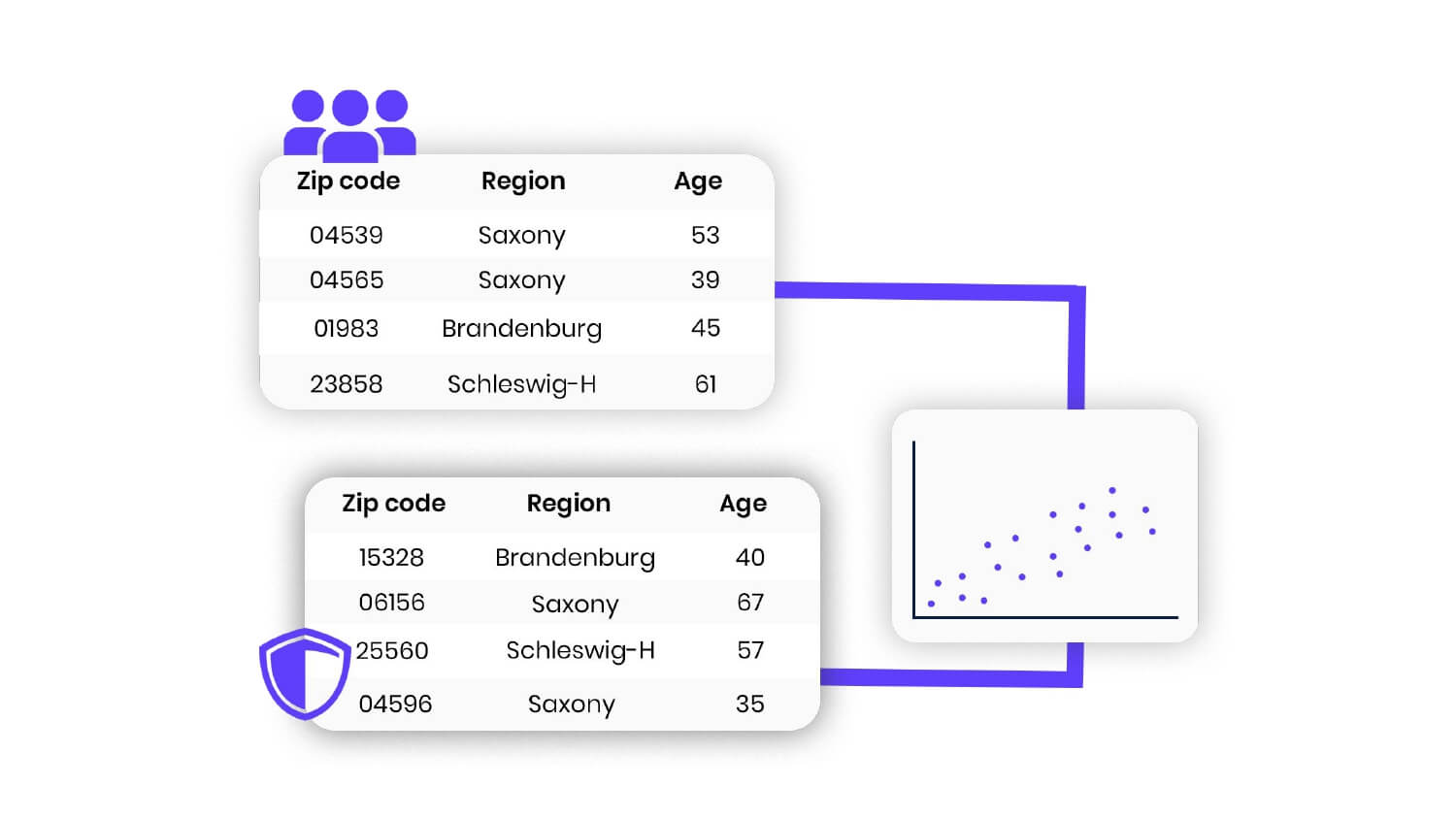
Dynamic data masking is applied to data in real-time and only affects the data returned to authorized users who request it. The actual data in the database remains unchanged (see Figure 1). Static data masking, on the other hand, creates a copy of the database with the sensitive data replaced by masked data. Users can not view the original data and only access the masked version (see figure 2).
It does not, however, prevent attackers from using other data sets to re-identify individuals via linkage attacks or inference attacks by combining the data sets based on the values in unmasked fields. Rather, it requires the data, its use, and its users to be restricted/sequestered to prevent masked records from being combined with information to reveal identities or other sensitive information.
There are two approaches to masking: dynamic and static. Dynamic data masking is a method of obscuring sensitive data in a database by replacing the sensitive data with a masked version in real-time while the actual sensitive data remains unchanged in the database.
Static data masking is a method that involves creating a copy of a database with sensitive data replaced by masked data, which is then used for testing or development purposes. The original database with sensitive data remains unchanged.
The environment (production vs. non-production), the type of processing (real-time vs batch processing), and the level of granularity in the analysis or the masking requirements usually determine the choice of technique.
Dynamic data masking is applied to data in real-time and only affects the data returned to authorized users who request it. The actual data in the database remains unchanged (see Figure 1). Static data masking, on the other hand, creates a copy of the database with the sensitive data replaced by masked data. Users can not view the original data and only access the masked version (see figure 2).
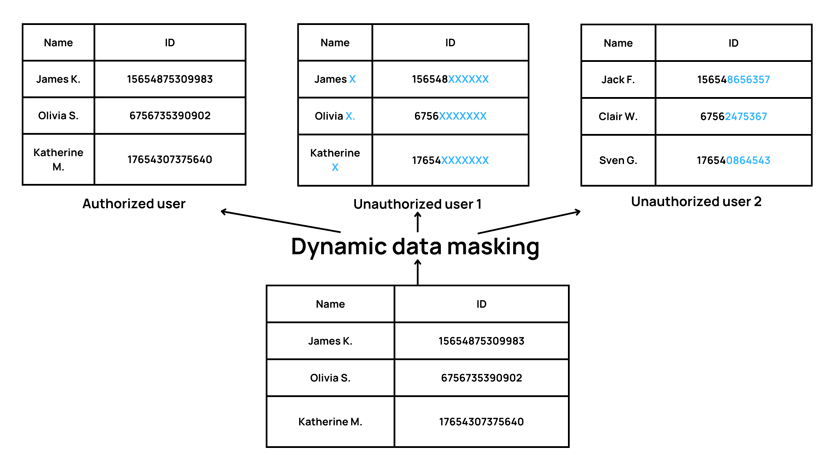
Figure 1: Dynamic data masking illustration
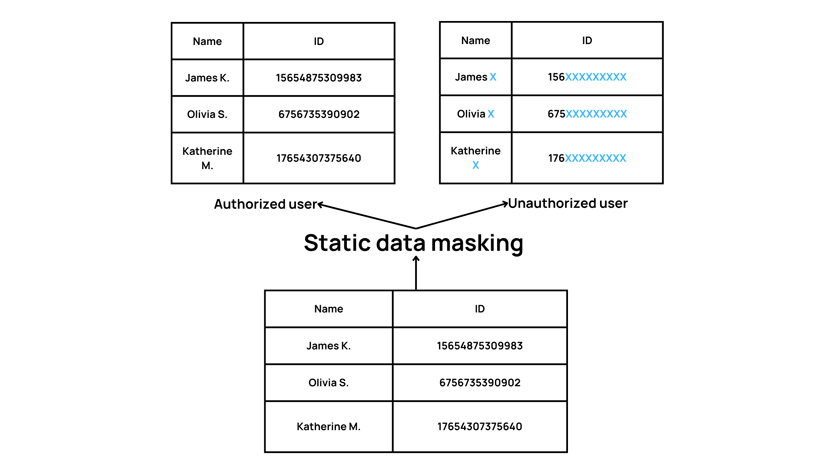
Figure 2: Static data masking illustration
Dynamic data masking can be applied to data in a database at the field level, while static data masking is typically applied to a whole database or a subset of data in a database. Dynamic data masking can be configured to apply different masking rules to different users or groups of users, while static data masking applies the same masking rules to all users.
We present several examples of static data masking methods below, also known as data obfuscation methods: data randomization, data shuffling, data substitution, data tokenization or pseudonymization, data hashing, data truncation, and data redaction.
We present several examples of static data masking methods below, also known as data obfuscation methods: data randomization, data shuffling, data substitution, data tokenization or pseudonymization, data hashing, data truncation, and data redaction.
When to use which data masking techniques?
If you are working with sensitive data, your compliance team will request that appropriate measures are taken to safeguard the information. The goal is to strive for non-identifiable data, which is better for security and also satisfies the requirements of personal data regulations. Masking techniques are commonly used to achieve this goal. It is important to note, however, that the level of protection provided by these techniques varies and that different techniques do not offer the same level of protection.
Data privacy protection is not a one-size-fits-all solution. It involves a spectrum of methods, mechanisms, and tools that provide varying levels of protection and pose different risks of re-identification. These tools are used to achieve different levels of data protection.
Data privacy protection is not a one-size-fits-all solution. It involves a spectrum of methods, mechanisms, and tools that provide varying levels of protection and pose different risks of re-identification. These tools are used to achieve different levels of data protection.
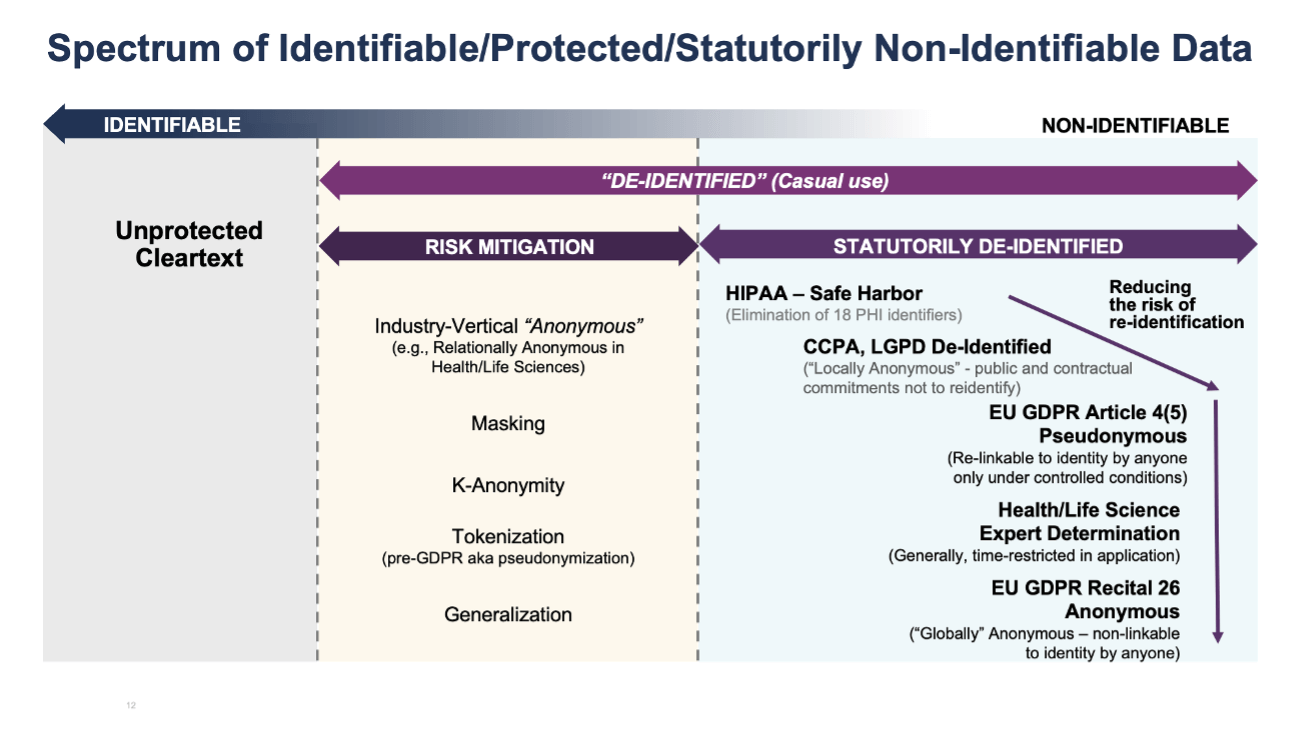
Before we dive into the list of data masking techniques, it is important to distinguish between “risk mitigated” and “statutorily de-identified” data, as this distinction has technical and legal implications.
The primary difference between these groups is that techniques in the "risk mitigated" category provide some protection against the re-identification of individuals but fall short of meeting the legal standards of data privacy policies regarding the re-identification risks.
While methods such as data masking, k-anonymity, tokenization, and generalization are valid and useful, they should be used judiciously for use cases involving more complex processing environments, including sharing, combining, and enriching multiple data sources and data sets, as these methods can leave the data vulnerable to re-identification risk. They remain a relevant protection layer for sensitive data in test environments, for example.
Below is a list of commonly used data masking techniques that could help you protect data.
The primary difference between these groups is that techniques in the "risk mitigated" category provide some protection against the re-identification of individuals but fall short of meeting the legal standards of data privacy policies regarding the re-identification risks.
While methods such as data masking, k-anonymity, tokenization, and generalization are valid and useful, they should be used judiciously for use cases involving more complex processing environments, including sharing, combining, and enriching multiple data sources and data sets, as these methods can leave the data vulnerable to re-identification risk. They remain a relevant protection layer for sensitive data in test environments, for example.
Below is a list of commonly used data masking techniques that could help you protect data.
List of data masking techniques
Data randomization
Data randomization is a data masking technique used to obscure sensitive data by replacing it with random data that conforms to the same format as the original data.
For example, consider a database containing personal information such as names, addresses, and dates of birth. To protect this sensitive data, data randomization can be used to replace the names, addresses, and dates of birth with randomly generated names, addresses, and dates of birth. This allows authorized users to access the type of data they need without exposing the original sensitive data.
Data shuffling
Data shuffling, or scrambling, is a data masking technique that involves replacing sensitive data with a version of the data that has been rearranged in some way.
For instance, the letters in a name could be shuffled to create a new name, or the digits in an address could be rearranged to create a new address. The name "John Smith" could be shuffled into "Smijh Tohn". The address "123 Main Street" could be shuffled into "321 Tnias Mrteet".
Data tokenization or pseudonymization
Tokenization is a technique that is used to protect sensitive data by replacing it with a modified version that does not contain any sensitive information.
Data tokenization specifically replaces the sensitive data with a randomly generated value, known as a token. Tokenization involves having a system that retrieves and reconnects the token back to the original data.
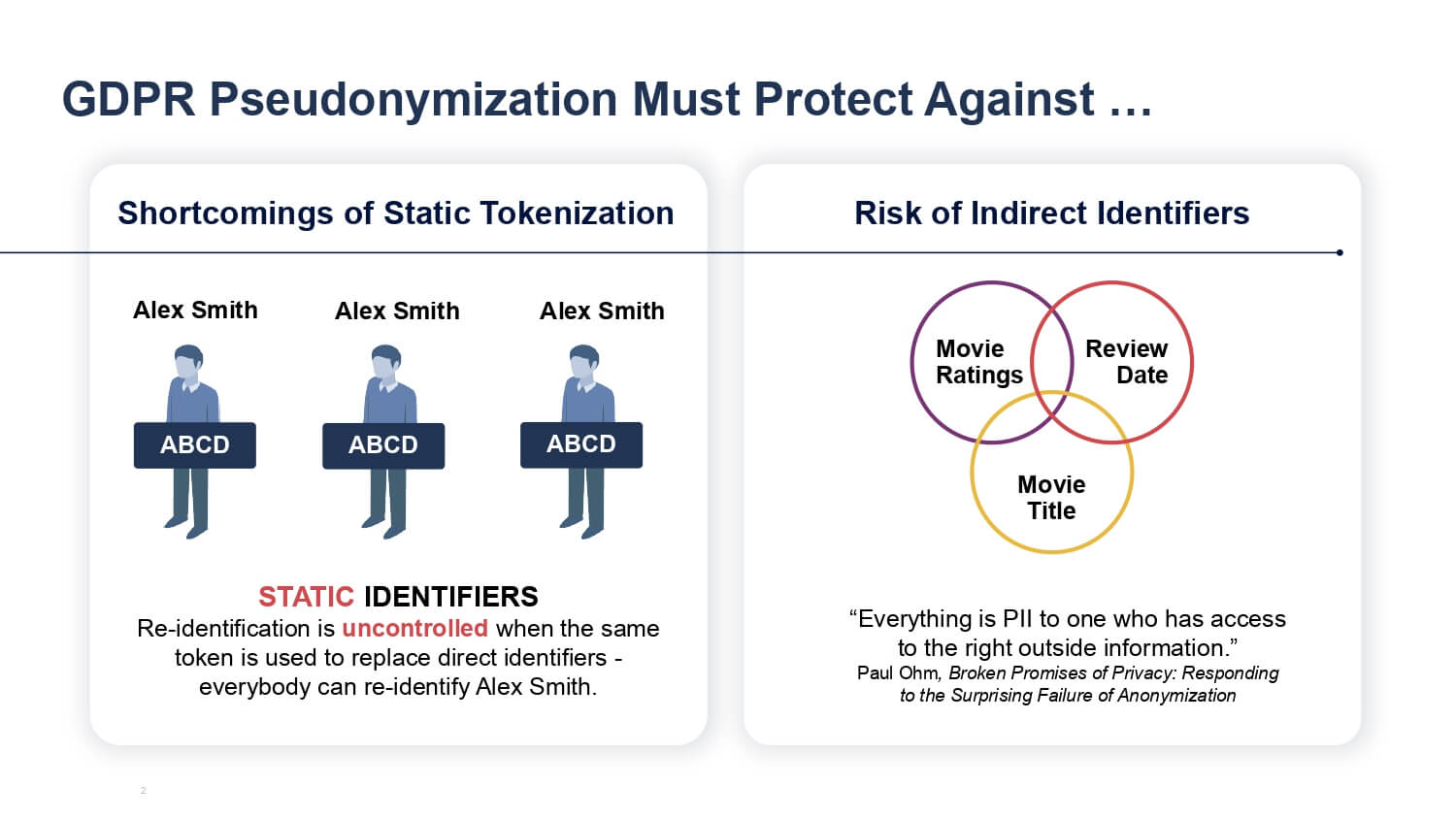
For example, to protect customers' credit card information from theft, a retailer replaces credit card numbers with unique tokens that have no meaningful correlation to the original number. The tokens are stored in a secure database instead of the actual credit card numbers. When a customer makes a purchase, the token is used to retrieve the credit card number from the tokenization system for payment processing. This way, if a retailer’s database is ever breached, the attackers would only obtain meaningless tokens instead of actual credit card numbers.
Tokenization is used to protect data while still allowing authorized users to access a modified version of it for purposes such as payment processing, data storage, and data transmission.
It is important to note that pseudonymization and tokenization as techniques differ from pseudonymization as defined in the GDPR.
Pseudonymization under the GDPR is also known as Statutory Pseudonymization and is a legal standard that a data set can meet or not meet. It requires that the entire data set be protected in such a way that the identity of data subjects can not be determined, except for with the use of re-linking data held separately and protected with technical and organizational measures. This is a much more complex state than simple tokenization.
Data hashing involves converting sensitive data into a fixed-size value using a mathematical function called a hash function. The hash value cannot be used to recreate the original data, but it can be used to verify the integrity of the data.
The hash value can be used to identify whenever two data attributes refer to the same value without exposing the underlying data. For example, in a dataset containing personal information about patients where names have been converted into a fixed-size value: the name "John Smith" is now the value "ef92b778bafe771e94a00b49d7d56935". It is possible to use the hash values to identify whenever two different datasets refer to this same patient (now referred to with the hash value) without being able to reverse engineer the original name "John Smith".
Data truncation involves truncating or cutting off sensitive data at a certain point to obscure it. For example, the last four digits of a credit card number could be truncated.
Truncation can protect data while allowing authorized users to access a portion of it. For example, to verify the identity of a customer using their account number while still protecting this sensitive data, data truncation can be used to obscure the middle eight digits of the account number. Accessing the first four and last four digits is enough to identify the account and verify the customer's identity.
Data redaction is a technique used to obscure sensitive data by blacking it out or removing it from a document or image. It can be used to protect a data set or data value while still allowing authorized users to access a portion of it.
For example, there may be a scenario where someone has a document containing sensitive information, but they need to share it with a third party. Data redaction tools can be used to black out the names, addresses, and social security numbers of the individuals while leaving the rest of the document intact. The third party will not be able to see the sensitive information but will still be able to access the relevant information in the document.
Tokenization is used to protect data while still allowing authorized users to access a modified version of it for purposes such as payment processing, data storage, and data transmission.
It is important to note that pseudonymization and tokenization as techniques differ from pseudonymization as defined in the GDPR.
Pseudonymization under the GDPR is also known as Statutory Pseudonymization and is a legal standard that a data set can meet or not meet. It requires that the entire data set be protected in such a way that the identity of data subjects can not be determined, except for with the use of re-linking data held separately and protected with technical and organizational measures. This is a much more complex state than simple tokenization.
Data hashing
Data hashing involves converting sensitive data into a fixed-size value using a mathematical function called a hash function. The hash value cannot be used to recreate the original data, but it can be used to verify the integrity of the data.
The hash value can be used to identify whenever two data attributes refer to the same value without exposing the underlying data. For example, in a dataset containing personal information about patients where names have been converted into a fixed-size value: the name "John Smith" is now the value "ef92b778bafe771e94a00b49d7d56935". It is possible to use the hash values to identify whenever two different datasets refer to this same patient (now referred to with the hash value) without being able to reverse engineer the original name "John Smith".
Data truncation
Data truncation involves truncating or cutting off sensitive data at a certain point to obscure it. For example, the last four digits of a credit card number could be truncated.
Truncation can protect data while allowing authorized users to access a portion of it. For example, to verify the identity of a customer using their account number while still protecting this sensitive data, data truncation can be used to obscure the middle eight digits of the account number. Accessing the first four and last four digits is enough to identify the account and verify the customer's identity.
Data redaction
Data redaction is a technique used to obscure sensitive data by blacking it out or removing it from a document or image. It can be used to protect a data set or data value while still allowing authorized users to access a portion of it.
For example, there may be a scenario where someone has a document containing sensitive information, but they need to share it with a third party. Data redaction tools can be used to black out the names, addresses, and social security numbers of the individuals while leaving the rest of the document intact. The third party will not be able to see the sensitive information but will still be able to access the relevant information in the document.
Other techniques to protect data
Data generalization
Data generalization is used to obscure sensitive data by replacing it with more general or aggregated data. The goal of generalization is to reduce the level of detail in the data while preserving the data set’s statistical properties and relevance.
Data generalization can be achieved by replacing specific values with more general categories or by aggregating data into broader, less identifying time periods or geographic regions. For example, a dataset containing specific ages could be generalized by replacing the specific ages with age ranges (e.g., "18-24", "25-34", "35-44", etc.). We can also aggregate data into a hierarchy of increasingly general categories. For example, a dataset containing specific cities could be generalized by aggregating them into states, regions, or countries.
Data generalization involves reducing the level of detail in the data. This can result in a loss of precision and accuracy, which can make it more difficult to analyze and interpret the data, and may limit the insights that can be gained from it.
Data encryption
Encryption is another approach to protecting data in which one converts sensitive data into a scrambled format that can only be accessed by authorized users with the proper decryption key. The scrambled data, called ciphertext, cannot be read or understood by anyone without the decryption key.
The encryption process uses secret keys to transform the information in a way that reduces the risk of misuse while maintaining confidentiality for a given period of time. The transformations applied by encryption algorithms are designed to be reversible, which allows authorized users to access the original data through the process of decryption.
Encryption is used to ensure the confidentiality of data transmitted over a network and to protect data at rest, such as data stored in a database. Encryption is an effective way to protect data in transit because it ensures the confidentiality of the data and makes it much more difficult for unauthorized parties to access the data.
Synthetic data
Synthetic data is a technique that involves generating artificial data that mimics the statistical properties and patterns of the original data but does not contain any sensitive information. Synthetic data is produced by determining the properties of the original data set and then creating a completely new data set with fabricated data points that match the original data set’s properties.
Synthetic data can be used to protect the privacy of individuals and organizations while allowing authorized users to access a modified version of the data for research, testing, and other purposes.
For example, synthetic data can allow a data analyst team to analyze customer transaction data while protecting customers’ privacy. From a dataset that includes information about the customer's name, address, email, and purchase history, it’s possible to create a new synthetic version that preserves the statistical patterns of the original data, such as the distribution of customer ages, the types of products purchased, and the average purchase amount. The analyst team can use the synthetic data to analyze and interpret it, but they will not be able to identify or contact any specific customers.
In conclusion, data masking techniques are important in protecting data from unauthorized access or compromise in relatively simple use cases (i.e., those not involving more complex processing, including sharing, combining, and enriching multiple data sources and data sets).
Although data masking is effective in concealing sensitive information, it does not offer complete protection against attackers who can still use other data sets to re-identify individuals through linkage or inference attacks. To prevent masked records from being combined with other information and revealing sensitive information, data masking requires the data, its use, and its users to be restricted or sequestered. However, this requirement contradicts the needs of many prevalent use cases that require data to flow freely and involve dynamically changing data sources, processes, and processors.
Data privacy protection is not a one-size-fits-all solution, and different techniques offer varying levels of protection. Apart from data masking, various data protection methods and techniques can be combined to provide improved protection and usefulness based on the specific use case of your data.
For example, synthetic data can allow a data analyst team to analyze customer transaction data while protecting customers’ privacy. From a dataset that includes information about the customer's name, address, email, and purchase history, it’s possible to create a new synthetic version that preserves the statistical patterns of the original data, such as the distribution of customer ages, the types of products purchased, and the average purchase amount. The analyst team can use the synthetic data to analyze and interpret it, but they will not be able to identify or contact any specific customers.
In conclusion, data masking techniques are important in protecting data from unauthorized access or compromise in relatively simple use cases (i.e., those not involving more complex processing, including sharing, combining, and enriching multiple data sources and data sets).
Although data masking is effective in concealing sensitive information, it does not offer complete protection against attackers who can still use other data sets to re-identify individuals through linkage or inference attacks. To prevent masked records from being combined with other information and revealing sensitive information, data masking requires the data, its use, and its users to be restricted or sequestered. However, this requirement contradicts the needs of many prevalent use cases that require data to flow freely and involve dynamically changing data sources, processes, and processors.
Data privacy protection is not a one-size-fits-all solution, and different techniques offer varying levels of protection. Apart from data masking, various data protection methods and techniques can be combined to provide improved protection and usefulness based on the specific use case of your data.




