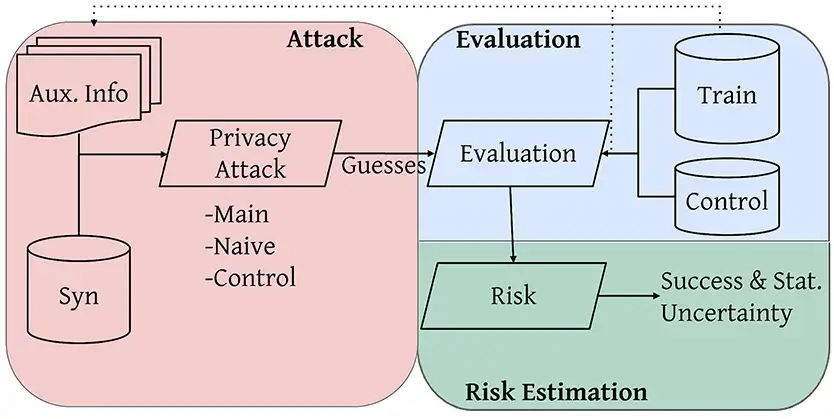
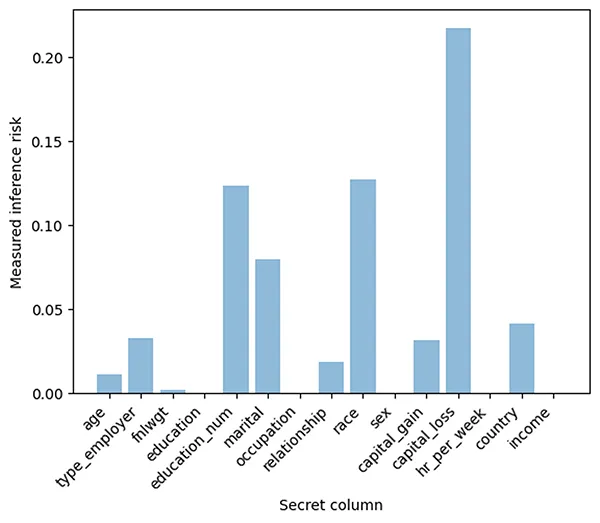
In this article, we introduce Anonymeter, an open-source tool developed by Anonos for organizations to evaluate the privacy risks of their synthetic data.
The National Commission on Informatics and Liberty (CNIL), France's data protection authority, recently assessed Anonymeter's effectiveness in evaluating privacy risks in anonymized and pseudonymized data. The CNIL Technology Expert Commission noted that the data controller should use the results produced by Anonymeter to decide whether the residual risks of re-identification are acceptable and whether the dataset can be considered anonymous.
In this blog post, we will discuss:
- The privacy and legal challenges of synthetic data generation
- Anonymeter’s ability to quickly evaluate privacy risks
- How to use Anonymeter and why we made it open source
The privacy and legal challenges of synthetic data
Synthetic data is a valuable resource for businesses looking to develop and enhance their data-driven applications while ensuring the privacy of their customers and sensitive data. Today, many enterprises utilize synthetic data as an effective anonymization method to unlock new data sharing opportunities and gain competitive edges in their data operations.
However, complying with the legal requirements for data anonymization is a major challenge for enterprises. Evaluating privacy risks in synthetic data and interpreting technical risk assessments is complex, costly and time-consuming for compliance teams. Organizations must navigate the complex facets of the concept of re-identification to evaluate the risks associated with synthetic data. Data science teams may not have the necessary expertise to carry out this assessment effectively. The scale and diversity of synthetic data types, on the one hand, and the complexity and abundance of privacy metrics, on the other, make risk assessments a difficult task.
Additionally, interpreting the results of a privacy risk assessment in the eyes of regulatory frameworks can also reveal challenges. It requires specialized knowledge and expertise in data anonymization techniques, statistical analysis, and privacy regulations. The GDPR’s anonymization requirements stipulate that all means likely to be used for re-identification must be taken into account, and re-identification of a data subject in the dataset must no longer be possible. Still, there is no clear methodology or proposed threshold for defining re-identification, making it difficult to determine whether anonymization requirements have been met.
Anonymeter helps enterprises meet these challenges. It provides an easy-to-use framework to assess privacy risks in synthetic datasets. Anonymeter is used in the final stage of a synthetic data pipeline, ensuring that synthetic datasets are correctly anonymized and protected. It produces a comprehensive report summarizing the privacy risks associated with a dataset and providing indications of how to mitigate them.
However, complying with the legal requirements for data anonymization is a major challenge for enterprises. Evaluating privacy risks in synthetic data and interpreting technical risk assessments is complex, costly and time-consuming for compliance teams. Organizations must navigate the complex facets of the concept of re-identification to evaluate the risks associated with synthetic data. Data science teams may not have the necessary expertise to carry out this assessment effectively. The scale and diversity of synthetic data types, on the one hand, and the complexity and abundance of privacy metrics, on the other, make risk assessments a difficult task.
Additionally, interpreting the results of a privacy risk assessment in the eyes of regulatory frameworks can also reveal challenges. It requires specialized knowledge and expertise in data anonymization techniques, statistical analysis, and privacy regulations. The GDPR’s anonymization requirements stipulate that all means likely to be used for re-identification must be taken into account, and re-identification of a data subject in the dataset must no longer be possible. Still, there is no clear methodology or proposed threshold for defining re-identification, making it difficult to determine whether anonymization requirements have been met.
Anonymeter helps enterprises meet these challenges. It provides an easy-to-use framework to assess privacy risks in synthetic datasets. Anonymeter is used in the final stage of a synthetic data pipeline, ensuring that synthetic datasets are correctly anonymized and protected. It produces a comprehensive report summarizing the privacy risks associated with a dataset and providing indications of how to mitigate them.
Assessing the privacy risks of synthetic data with Anonymeter
Anonymeter is a software tool that implements different privacy attacks against synthetic tabular datasets and uses these attacks to estimate the re-identification risk. It provides organizations with comprehensive evaluations of privacy risks and demonstrates compliance with the GDPR's requirements for anonymized synthetic datasets.
Anonymeter evaluates the singling out, linkability, and inference risks associated with synthetic datasets. It then produces a report summarizing the privacy risks associated with the dataset and provides recommendations for mitigating those risks.
Anonymeter evaluates the singling out, linkability, and inference risks associated with synthetic datasets. It then produces a report summarizing the privacy risks associated with the dataset and provides recommendations for mitigating those risks.

Privacy is a multi-faceted concept reflected in the availability of dozens of different privacy metrics. However, for most of these metrics, it is unclear how they translate into privacy implications in practice and what concrete privacy risks exist for individual data records.
Anonymeter is an empirical attack-based evaluation. It measures privacy risks by looking at how easy it is to attack the records in the original sensitive dataset from the synthetic one. Such an attack-based evaluation makes it easy to evaluate the context underlying the privacy risk and its practical implications.
Another distinguishing characteristic of Anonymeter is that it can differentiate between synthetic data privacy and utility as not all the information contained in the synthetic data constitutes a privacy breach. By making this distinction, Anonymter measures privacy risks in a sensitive and meaningful way.
Anonymeter is an empirical attack-based evaluation. It measures privacy risks by looking at how easy it is to attack the records in the original sensitive dataset from the synthetic one. Such an attack-based evaluation makes it easy to evaluate the context underlying the privacy risk and its practical implications.
Another distinguishing characteristic of Anonymeter is that it can differentiate between synthetic data privacy and utility as not all the information contained in the synthetic data constitutes a privacy breach. By making this distinction, Anonymter measures privacy risks in a sensitive and meaningful way.

Finally, unlike other approaches that attempt to assess the privacy risks associated with synthetic data generation processes (such as membership inference attacks), Anonymeter evaluates the privacy risks of synthetic data by analyzing the output of the data generation process, the synthetic data itself. It provides, therefore, a more direct measurement of the risk.
Anonymeter is relevant for enterprises using synthetic data due to its comprehensive and scalable framework for assessing and mitigating privacy risks.
The tool is designed to be widely usable and to provide interpretable results, requiring minimal manual configuration and no expert knowledge besides basic data analysis skills. It also applies to a wide range of datasets, numerical and categorical data types. It is the first tool to comprehensively evaluate the three key indicators of factual anonymization for synthetic data, allowing organizations to meet regulatory requirements.
Anonymeter is relevant for enterprises using synthetic data due to its comprehensive and scalable framework for assessing and mitigating privacy risks.
The tool is designed to be widely usable and to provide interpretable results, requiring minimal manual configuration and no expert knowledge besides basic data analysis skills. It also applies to a wide range of datasets, numerical and categorical data types. It is the first tool to comprehensively evaluate the three key indicators of factual anonymization for synthetic data, allowing organizations to meet regulatory requirements.