





Many organizations believe that data security and privacy measures get in the way of speedy decision-making and innovation. However, this doesn’t need to be the case with a modern approach to data governance and protection.
Most organizations aspire to generate data insights and value from seven universal secondary uses of data, and their position on the continuum of these use cases indicates their maturity in being able to accomplish objectives. However, they often are blocked by three main obstacles.
The right technical controls for data protection can improve data access management and thereby expand and expedite almost any secondary use for creating more business value. One important consideration for organizations is how they protect data in use, which can boost data availability and open up a broader range of data operations to support more of their business goals.
The right technical controls for data protection can improve data access management and thereby expand and expedite almost any secondary use for creating more business value. One important consideration for organizations is how they protect data in use, which can boost data availability and open up a broader range of data operations to support more of their business goals.
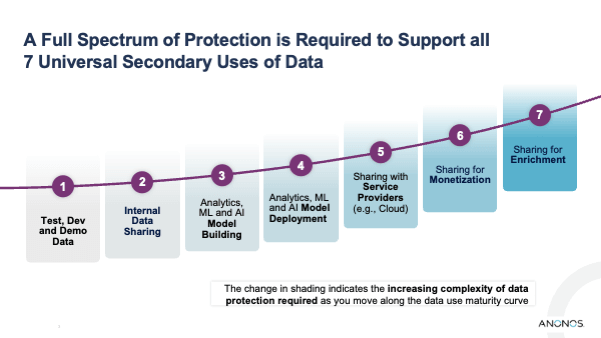
The Seven Universal Secondary Uses of Data
The seven universal secondary uses of data are applicable across organizations and industries, regardless of jurisdiction. Any enterprise dealing with data wants to use it in one or more of these seven ways:
Without appropriate data privacy controls, the more complex secondary uses remain unlawful and unable to be utilized. Legal and technical requirements increase with each secondary use along the curve.
- Using data for testing
- Internal data sharing
- Data analytics, machine learning, and AI model building
- Data analytics, machine learning, and AI model deployment
- Sharing data with service providers
- Sharing data for monetization
- Sharing data for enrichment
Without appropriate data privacy controls, the more complex secondary uses remain unlawful and unable to be utilized. Legal and technical requirements increase with each secondary use along the curve.
During Anonos’ recent webinar on the business benefits of data security and privacy, the majority of attendees noted that (1) sharing data with third parties for monetization; (2) sharing data with a third-party service provider; and (3) sharing data internally across business boundaries are the most challenging secondary uses to get approved.
The Three Data Use Obstacles
Organizations also face common barriers to accomplishing these seven universal secondary uses of data, and they also may have issues with data availability. For example, data that goes stale diminishes ROI. Data utilization at the highest level can be slow and expensive with inappropriate controls, as approvals from legal and privacy teams are denied in many cases.
The three primary obstacles to making the most out of data are:
The three primary obstacles to making the most out of data are:
- Data must be protected when in use: Most organizations protect their sensitive data when it is in storage and in transit, with methods such as data encryption, data masking and access controls. However, once data is de-encrypted for use, it becomes vulnerable and open to misuse and breach. This makes getting approvals difficult for complex use cases that require data processing, enrichment and sharing. In addition, costs for cyber insurance and breach protection methods are high.
- Data is too sparse or biased: In some cases, datasets are simply too sparse or biased to use for advanced data processing methods. In addition, sometimes data subjects exercise their right to be forgotten, or data is withdrawn or withheld in other ways. This can leave datasets with less utility, leaving the organization unable to compete with others who may be more advanced in their processing capabilities.
- Satisfying regulatory requirements for lawful international transfer and surveillance-proof processing: The Schrems II case struck down the EU-U.S. Privacy Shield, establishing that the data of EU citizens can’t be processed if there’s a risk of data surveillance or access by other governments, such as through the U.S. CLOUD Act. Organizations must use technical approaches that prevent surveillance or access, otherwise international data transfers may be unlawful. Without appropriate technical measures to protect and monitor data privacy, organizations can’t progress up the data use maturity curve to global data sharing, monetization and enrichment. Importantly, this also prevents sharing data with service providers such as cloud SaaS and IaaS providers.
Attendees of the webinar on the business benefits of data privacy and security hosted by Anonos indicated that protecting data when in use is the most important imperative for capturing secondary use value, followed by remediating data and satisfying requirements for surveillance-proof processing.
Overcoming the Main Data Use Obstacles
For organizations to overcome the three data use obstacles to accomplishing all seven universal secondary uses of data, the use of data privacy controls and data security management is necessary. Specifically, technical measures should be adopted to protect data in use.
Approaching data security and data privacy with only policies and access controls can prevent some issues, but they don’t power additional secondary uses and won’t always prevent breaches from occurring. That’s why a robust data protection strategy should include technical controls.
Embedding technical controls that move with data for protection while in use can unlock additional secondary uses of data. Effective controls equate to competitive advantage.
Approaching data security and data privacy with only policies and access controls can prevent some issues, but they don’t power additional secondary uses and won’t always prevent breaches from occurring. That’s why a robust data protection strategy should include technical controls.
Embedding technical controls that move with data for protection while in use can unlock additional secondary uses of data. Effective controls equate to competitive advantage.
Overcoming Obstacle 1: Protecting Data in Use
Protecting data in use is possible with statutory pseudonymization, as set forth in the General Data Protection Regulation (GDPR). And its application is rewarded with various legal and operational benefits, such as reduced disclosure obligations in the event of a breach.
Various legal bodies, such as the European Data Protection Board, recommend the use of statutory pseudonymization to protect data in use.
Tools that can protect data in use power more secondary uses and also provide significant cost reductions with regard to such expenses as cyber insurance.
Controls and tools make sure that if data breaches occur, or an internal actor attempts to misuse data, the type of data that is lost or obtained is unusable by the unauthorized party. Applying appropriate technical methods can therefore allow approvals to be made faster (as the risks are lower) and prevent negative outcomes. These faster approvals allow organizations to gain greater ROI on data.
During the Anonos’ webinar on the business benefits of data privacy and security, Spencer Ward, Manager II Technology at Elevance Health, noted that “having the apparatus to stop saying ‘no’ to important secondary uses can result in a 3X or 4X increase in business value or ROI on data upfront.”
Various legal bodies, such as the European Data Protection Board, recommend the use of statutory pseudonymization to protect data in use.
Tools that can protect data in use power more secondary uses and also provide significant cost reductions with regard to such expenses as cyber insurance.
Controls and tools make sure that if data breaches occur, or an internal actor attempts to misuse data, the type of data that is lost or obtained is unusable by the unauthorized party. Applying appropriate technical methods can therefore allow approvals to be made faster (as the risks are lower) and prevent negative outcomes. These faster approvals allow organizations to gain greater ROI on data.
During the Anonos’ webinar on the business benefits of data privacy and security, Spencer Ward, Manager II Technology at Elevance Health, noted that “having the apparatus to stop saying ‘no’ to important secondary uses can result in a 3X or 4X increase in business value or ROI on data upfront.”
Overcoming Obstacle 2: Remedying Sparse or Biased Data
Remedying sparse or biased data can be solved with technical methods too. The use of statutory pseudonymization, or the creation of additional data sets with the use of synthetic data, can ensure that data sets are comprehensive and representative.
For example, the GDPR allows data to be used for secondary purposes if an organization can show it has a “legitimate interest” in the data’s use. To comply with secondary processing requirements, the organization must show it has balanced the rights of the data subject with its rights to use the data. This balancing test can tip in favor of the data controller by applying strong data protection methods to ensure that harm to the data subject can’t occur because personally identifiable information (PII) is well protected.
Such approaches as statutory pseudonymization allow you to change personally identifiable information or other sensitive data into a format that retains information value but without relinking to the individual or data subject. Synthetic data creates replica datasets for testing or modeling that overcome the limitations of original data.
Both statutory pseudonymization and synthetic data help an organization set itself apart, plus prevent operational difficulties that slow down innovation and achieve regulatory compliance.
For example, the GDPR allows data to be used for secondary purposes if an organization can show it has a “legitimate interest” in the data’s use. To comply with secondary processing requirements, the organization must show it has balanced the rights of the data subject with its rights to use the data. This balancing test can tip in favor of the data controller by applying strong data protection methods to ensure that harm to the data subject can’t occur because personally identifiable information (PII) is well protected.
Such approaches as statutory pseudonymization allow you to change personally identifiable information or other sensitive data into a format that retains information value but without relinking to the individual or data subject. Synthetic data creates replica datasets for testing or modeling that overcome the limitations of original data.
Both statutory pseudonymization and synthetic data help an organization set itself apart, plus prevent operational difficulties that slow down innovation and achieve regulatory compliance.
Overcoming Obstacle 3: Satisfying the Legal Requirements for International Data Transfer
Technical methods also satisfy the legal requirements for international transfer. When the EU-U.S. Privacy Shield was struck down, the European Data Protection Board specifically recommended the use of encryption for protecting data in transit and statutory pseudonymization for the lawful international transfer and processing of sensitive data.
Data must be protected from government surveillance agencies of non-EEA countries - the application of legal remedies and fines after access has already occurred is insufficient.
The use of data privacy controls or data management tools can ensure that organizational operations are not interrupted, and can provide data security and assurances to partners within the data supply chain.
Data privacy tools allow organizations to work internationally without fear of legal and compliance issues, opening new markets, speeding up data access, and allowing global data sharing, including the use of data storage and processing in the U.S. cloud.
Gary LaFever, Co-CEO & General Counsel at Anonos states: “With technical controls, you don't have to say ‘no’ to data use requests. There is no single data use that couldn't be approved with the right combination of contractual and technical controls.”
Data must be protected from government surveillance agencies of non-EEA countries - the application of legal remedies and fines after access has already occurred is insufficient.
The use of data privacy controls or data management tools can ensure that organizational operations are not interrupted, and can provide data security and assurances to partners within the data supply chain.
Data privacy tools allow organizations to work internationally without fear of legal and compliance issues, opening new markets, speeding up data access, and allowing global data sharing, including the use of data storage and processing in the U.S. cloud.
Gary LaFever, Co-CEO & General Counsel at Anonos states: “With technical controls, you don't have to say ‘no’ to data use requests. There is no single data use that couldn't be approved with the right combination of contractual and technical controls.”
Data Without the Drama
Anonos provides software that moves organizations along the data use maturity curve, unlocking all seven secondary uses of datause cases. Anonos’ Data Embassy platform embeds technical controls within the data that move with it wherever it travels.
Based on the statutory requirements of the General Data Protection Regulation (GDPR), Data Embassy transforms source datasets into Variant Twins: non-identifiable yet 100% accurate variations of the source data that meet use-case needs and comply with the applicable data regulations. Therefore, using Variant Twins overcomes all three data use obstacles outlined above: they protect data in use, retain the information value of data to prevent sparse datasets, and meet the requirements for lawful international data transfers, including using the cloud.
Data security and privacy don’t require a tradeoff. As Spencer Ward states, “Knowing that you have these tools in your toolbelt to be able to move on the secondary uses fast, [is] a game changer. I think that will separate leading enterprises in the space: those that are actually able to pull off these higher level maturity secondary uses from others that can't.”
Based on the statutory requirements of the General Data Protection Regulation (GDPR), Data Embassy transforms source datasets into Variant Twins: non-identifiable yet 100% accurate variations of the source data that meet use-case needs and comply with the applicable data regulations. Therefore, using Variant Twins overcomes all three data use obstacles outlined above: they protect data in use, retain the information value of data to prevent sparse datasets, and meet the requirements for lawful international data transfers, including using the cloud.
Data security and privacy don’t require a tradeoff. As Spencer Ward states, “Knowing that you have these tools in your toolbelt to be able to move on the secondary uses fast, [is] a game changer. I think that will separate leading enterprises in the space: those that are actually able to pull off these higher level maturity secondary uses from others that can't.”
Conclusion
Most organizations work across seven universal secondary uses of data but find themselves blocked by one or more of three primary obstacles to using their data. Using a combination of data privacy and security techniques, such as those available within Anonos’ Data Embassy toolbox, organizations can successfully employ all seven universal secondary uses of data without running into data security and compliance issues. Ultimately, these data protection controls allow organizations to save money, operate more efficiently, and establish competitive differentiation.
Would you like to schedule a briefing so we can talk about your specific data drama and how we can help?




