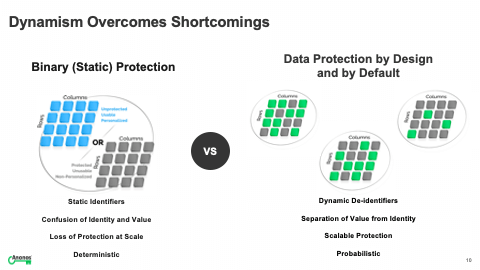
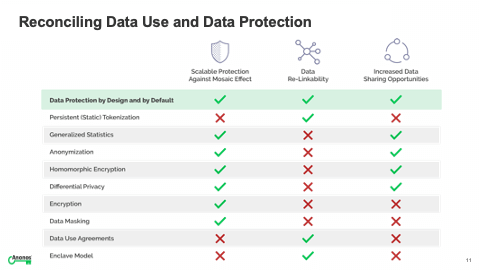
[08:45] The next slide, which is my favorite slide because it blinks, on the left hand side, the bright vivid blue represents usable data. Below that to the right is the dark gray, and this is meant to highlight that in a static approach to data protection using static identifiers, there's a confusion between identity and information. I get one, I get the other. I can't split them apart. And you actually lose protection at scale, which I've mentioned earlier as you start to combine additional datasets.
[09:18] And lastly, the whole value proposition is deterministic where you rely on knowing that an individual is that specific individual. And if you go to the right hand side, what that's meant to highlight is each individual square is an individual cell of data. Sometimes it's needed. Sometimes it's not needed. Why is it even in the conversation? So, you've dynamically changed identifiers. You will notice on the left, I call them static identifiers. On the right, they're dynamic de-identifiers.
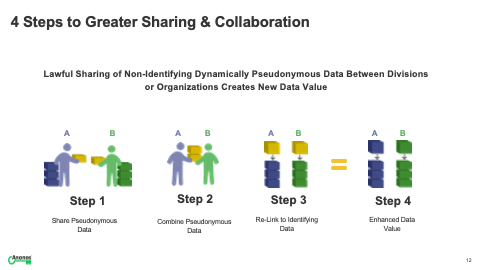
[09:49] What that means is because the identifier is changing, so if your name appeared - I had the prior example of three datasets that was ABCD, ABCD, and ABCD. Why isn't it ABCD, Q99 and DDID? Now each of the three datasets is anonymous. And unless you have permission to know that ABCD equals Q99 equals DDID, you don't know that. But you haven't lost the ability to re-link. And so, you actually are separating value from identity. And the more data that's added, the protection actually increases. And for most use cases, it's probabilistic. It's not deterministic, which is more than necessary for the desired use.

 Gary LaFever
Gary LaFever
 Malte Beyer-Katzenberger
Malte Beyer-Katzenberger
 Gwendal Le Grand
Gwendal Le Grand
 Dr. Alison Knight
Dr. Alison Knight











 62 min
62 min


