





Data protection is a crucial aspect of building trust in AI systems. Artificial intelligence (AI) requires the application of both ethical and regulatory boundaries, and it is essential that data and analytics leaders make use of all available tools and processes to meet these standards. This includes using tools that allow AI explainability/model monitoring, privacy, ModelOps, and AI application security.
The Gartner Market Guide for Artificial Intelligence Trust, Risk and Security Management (AI TRiSM), recently published in January 2023, noted that “by 2026, organizations that operationalize AI transparency, trust and security will see their AI models achieve a 50% improvement in terms of adoption, business goals and user acceptance.”
This blog post outlines what fair AI is, the frequently encountered problems with data privacy and security in deep learning, machine learning, and AI, and how data protection tools can improve AI fairness.
The Gartner Market Guide for Artificial Intelligence Trust, Risk and Security Management (AI TRiSM), recently published in January 2023, noted that “by 2026, organizations that operationalize AI transparency, trust and security will see their AI models achieve a 50% improvement in terms of adoption, business goals and user acceptance.”
This blog post outlines what fair AI is, the frequently encountered problems with data privacy and security in deep learning, machine learning, and AI, and how data protection tools can improve AI fairness.
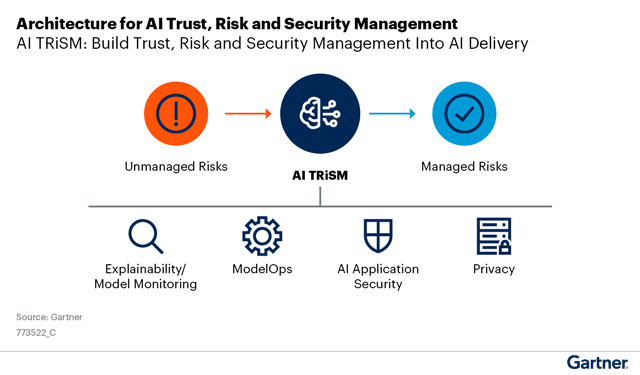
What is AI TRiSM?
AI TRiSM is an abbreviation for Artificial Intelligence (AI) Trust, Risk, and Security Management. Gartner organized this framework as a way to enable a better understanding of AI systems' issues and improvements, including AI fairness, privacy, and governance.
While AI is powerful and useful for a wide range of societal issues, it also needs to be developed and used in a safe, unbiased, free from errors, and ethical way.
While AI is powerful and useful for a wide range of societal issues, it also needs to be developed and used in a safe, unbiased, free from errors, and ethical way.
This graphic was published by Gartner, Inc. as part of a larger research document and should be evaluated in the context of the entire document. The Gartner document is available upon request from here.
GARTNER is a registered trademark and service mark of Gartner, Inc. and/or its affiliates in the U.S. and internationally and is used herein with permission. All rights reserved.
GARTNER is a registered trademark and service mark of Gartner, Inc. and/or its affiliates in the U.S. and internationally and is used herein with permission. All rights reserved.
What does AI fairness mean?
Fair AI is that which mitigates the presence of bias in the dataset. Fairness means that you assess each deep learning algorithm and eliminate potential biases from the data. If data is discovered to be biased, organizations should take steps to fix it. The use of different tools and practices can help this process to take place faster and more effectively.
The Gartner 2023 Market Guide outlines four crucial areas that can contribute to enhancing TRiSM and, consequently, building trust in AI:
The Gartner 2023 Market Guide outlines four crucial areas that can contribute to enhancing TRiSM and, consequently, building trust in AI:
- AI explainability/model monitoring: Gartner defines explainable AI as “a set of capabilities that produce details or reasons that clarify a model’s functioning for a specific audience.” This includes the model’s strengths and weaknesses, likely behaviour, and potential biases. Model monitoring uses tools to test for AI model inaccuracy, drift, biases, attacks, or mistakes that could be included in the model, preventing it from being trustworthy.
- Privacy: Any AI system often uses personal data and fails at the first step when it does not sufficiently protect it. According to Gartner, “two in five organizations had an AI privacy breach or security incident,” which highlights the importance of applying privacy controls to data that is used for AI model creation. The use of synthetic data and other privacy technologies to reduce re-identification risk can improve the privacy of datasets used for AI tools.
- ModelOps: ModelOps cover the governance and life cycle management of AI functions, analytics, and other decision models. AI systems can be improved with ModelOps by measuring performance and value.
- AI application security: Finally, AI application security programs test AI models against malicious attacks and check how robust the AI application is. AI models can also be trained to recognize and respond differently to attacks.
How to improve TRiSM?
Fairness in AI is not only important for data subjects, as a lack of security or privacy in AI use can have major impacts on organizations using it. In fact, Gartner notes that “by 2027, at least one global company will see its AI deployment banned by a regulator for noncompliance with data protection or AI governance legislation.”
The use of particular data in AI projects can be quite different from other projects and also has different data protection and ethical needs. For example, in many machine learning projects, large amounts of data are used to train models. With machine learning models, a common issue is that the model accidentally “learns” the wrong assumptions from a dataset. This can result in biases, discrimination, and add inefficiencies in machine learning processes.
In all cases, organizations must consider data protection issues, how representative the data is, whether bias has been incorporated into the model and whether the model and its outputs are clearly understood. AI and machine learning use incredibly large datasets when compared to many other projects, increasing the need for care.
Different technologies can help to improve the fairness and safety of AI and machine learning and will be increasingly used by organizations for data protection. Gartner even predicts that “by 2027, at least two vendors that provide AI risk management functionality will be acquired by enterprise risk management vendors providing broader functionality.”
The integration of TRiSM technologies into typical business risk management approaches will become commonplace.
The use of particular data in AI projects can be quite different from other projects and also has different data protection and ethical needs. For example, in many machine learning projects, large amounts of data are used to train models. With machine learning models, a common issue is that the model accidentally “learns” the wrong assumptions from a dataset. This can result in biases, discrimination, and add inefficiencies in machine learning processes.
In all cases, organizations must consider data protection issues, how representative the data is, whether bias has been incorporated into the model and whether the model and its outputs are clearly understood. AI and machine learning use incredibly large datasets when compared to many other projects, increasing the need for care.
Different technologies can help to improve the fairness and safety of AI and machine learning and will be increasingly used by organizations for data protection. Gartner even predicts that “by 2027, at least two vendors that provide AI risk management functionality will be acquired by enterprise risk management vendors providing broader functionality.”
The integration of TRiSM technologies into typical business risk management approaches will become commonplace.
How can privacy technologies be applied to AI?
One of the most important of the TRiSM issues from a regulatory perspective is that of privacy. The use of privacy-enhancing technologies (PETs), such as synthetic data or statutory pseudonymization, ensures that the personal information of individuals is not revealed or misused in the creation of AI systems or their use in production.
In many cases, the use of identifiable data is unnecessary and often illegal. PETs that ensure that identifiable data is not used, are one key aspect of improving the trustability and risk management of data used for AI processing.
For example, in some cases, synthetic data is a good option for training AI algorithms. Synthetic data can be used to fill gaps in real-world data sets, to compensate for low-quality data, or to create new data because other data couldn’t be used due to privacy regulations. It can also help to balance imbalanced datasets, reducing bias. Synthetic data improves the privacy of AI processing by replacing personal data with generated data that replicates the patterns of the original dataset but without personal information.
In other cases, statutory pseudonymization may be the right option for personal data protection. Statutory pseudonymization is a privacy-protected outcome achieved with a number of different techniques and is applied to an entire dataset to meet the requirements of the General Data Protection Regulation (GDPR).
Statutory pseudonymization can be used to de-identify data that is being used to train a machine learning or AI model but allows re-linking to identity to occur again later in authorized circumstances. For example, the model is being used for something such as healthcare data for a drug trial or a new treatment approach. If particular patients can be helped, their identities can be safely re-connected so that they can receive important care. In other cases, data is never re-linked and is simply de-identified in a highly secure and protected way so that the AI model can be trained on real data.
In many cases, the use of identifiable data is unnecessary and often illegal. PETs that ensure that identifiable data is not used, are one key aspect of improving the trustability and risk management of data used for AI processing.
For example, in some cases, synthetic data is a good option for training AI algorithms. Synthetic data can be used to fill gaps in real-world data sets, to compensate for low-quality data, or to create new data because other data couldn’t be used due to privacy regulations. It can also help to balance imbalanced datasets, reducing bias. Synthetic data improves the privacy of AI processing by replacing personal data with generated data that replicates the patterns of the original dataset but without personal information.
In other cases, statutory pseudonymization may be the right option for personal data protection. Statutory pseudonymization is a privacy-protected outcome achieved with a number of different techniques and is applied to an entire dataset to meet the requirements of the General Data Protection Regulation (GDPR).
Statutory pseudonymization can be used to de-identify data that is being used to train a machine learning or AI model but allows re-linking to identity to occur again later in authorized circumstances. For example, the model is being used for something such as healthcare data for a drug trial or a new treatment approach. If particular patients can be helped, their identities can be safely re-connected so that they can receive important care. In other cases, data is never re-linked and is simply de-identified in a highly secure and protected way so that the AI model can be trained on real data.
The need for a privacy-enhancing toolkit
In most cases, organizations need to use more than one PET, the choice of which depends on the way in which the data is being used. For example, statutory pseudonymization would be used if an organization needs data to be re-linkable to identity. For use cases in which data should not be re-linked, sanitization or anonymization are options. If real data is not necessary, synthetic data can be used instead.
Anonos’ Data Embassy was recognized in Gartner Market Guide for AI TRiSM for its Variant Twins technology and synthetic data capabilities. This platform enables organizations of all kinds to improve privacy and TRiSM for their AI modeling and production processes.
Data Embassy transforms personal data into protected Variant Twins, which can then be used for AI processing without fear, as they have appropriate data privacy controls applied no matter where the data travels or how it is used. Anonos also provides synthetic data for use cases in which synthetic data is a good solution.
When organizations use the correct data privacy technology toolkit, data privacy becomes an enablement rather than a restriction. This is because, as noted by Gartner, fair, secure, explainable AI leads to a 50% improvement in terms of adoption, business goals, and user acceptance.
Anonos’ Data Embassy was recognized in Gartner Market Guide for AI TRiSM for its Variant Twins technology and synthetic data capabilities. This platform enables organizations of all kinds to improve privacy and TRiSM for their AI modeling and production processes.
Data Embassy transforms personal data into protected Variant Twins, which can then be used for AI processing without fear, as they have appropriate data privacy controls applied no matter where the data travels or how it is used. Anonos also provides synthetic data for use cases in which synthetic data is a good solution.
When organizations use the correct data privacy technology toolkit, data privacy becomes an enablement rather than a restriction. This is because, as noted by Gartner, fair, secure, explainable AI leads to a 50% improvement in terms of adoption, business goals, and user acceptance.
Conclusion
The improvement of TRiSM for AI and the wider application of privacy controls to data are critical steps that need to take place for AI fairness to become widespread. Organizations are facing increased regulatory scrutiny and penalties, and concerted action is necessary sooner rather than later. Different technologies, such as Anonos Variant Twins, can make sense and be useful in different situations, depending on the context. In all cases, implementing fairness is essential for meeting the regulatory standards and supporting the ethical principles that instill human values into AI. In addition, it can help to protect your customers and your company’s reputation.




